
The team at Amazon Prime published an article where they explain their move from serverless microservices to a monolith, reducing costs by 90% and enabling them to properly scale their solution. Scaling that according to the article, serverless solutions AWS Lambdas and AWS Step Functions couldn’t deliver.
It took a week or so for the community to create a massive stir and write quite a few tweets and blogposts about it. Amongst others the article “Monoliths are not dinosaurs” by Werner Vogels (VP & CTO at Amazon) and “So many bad takes — What is there to learn from the Prime Video microservices to monolith story” by Adrian Cockcroft (former VP at Amazon). Both are good reads. Quite a few other articles seem to have understood that serverless and microservices are bad and monoliths are good. As always, it depends. An unrelated post by Rob Eisenberg called “The industrial hammer complex“, explains why they might and might not be.
What I’ve missed in the articles I’ve read so far, is not so much how the Amazon Prime evolved their architecture, but how they changed their development and physical views, but not so much their logical view. I’m talking about the 4+1 architectural view model that I’ve blogged about before. I’ll try to explain, but if you are unfamiliar with the 4+1 view model, I recommend reading that article first.
Now let me try to explain what I mean by saying the physical view might’ve changed, the logical view didn’t change that much.
Logical view
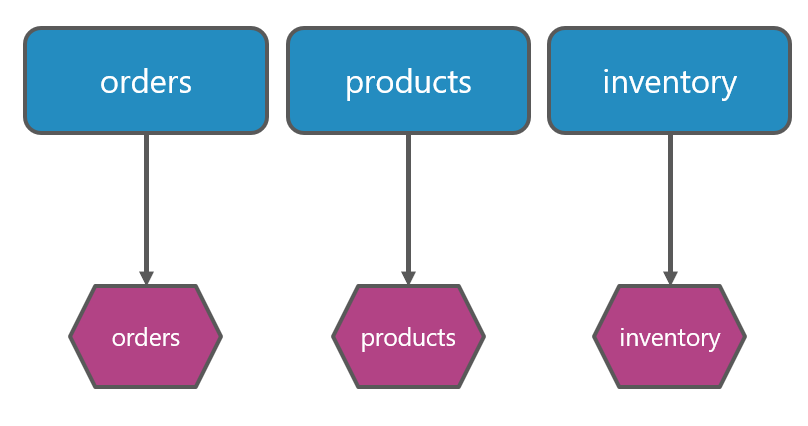
We might have a logical architecture with 3 components, as in the following image. At the top, we have our 3 random components called Orders, Products, and Inventory. Don’t worry about the naming too much, they’re just here as an example. Below each of them, there’s data storage. In the logical view, the technology hasn’t been decided yet. Maybe it’s SQL Server, maybe it’s CosmosDb or DynamoDb, or even in-memory storage. The logical view doesn’t involve those kinds of decisions.
Physical view
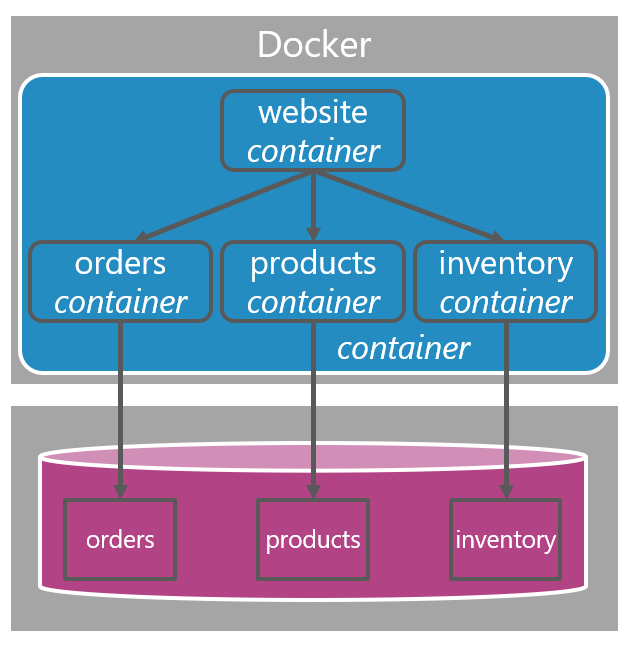
The physical view is the view that visualizes the deployment of our system. Usually, each component is visualized again including the data store accompanying it. For this article, not every detail matters in the image below, but we could imagine our components deployed and running as Docker containers with additionally a website as a Docker container. Below it, every component stores its data in a relational database. Let’s first focus on these relational databases. The image doesn’t show, but imagine there’s a single SQL Server instance and there are three databases; one for each component.
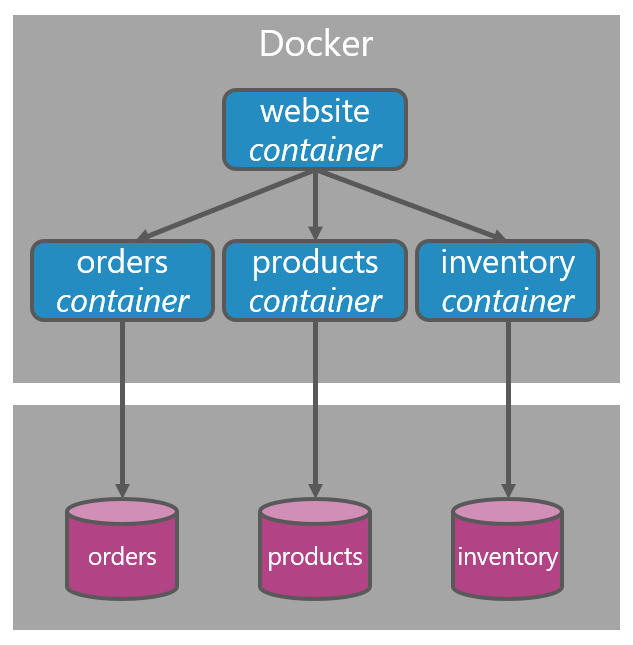
The Orders database is nothing more than a schema and accompanying data. The same for the Products and Inventory databases. We’ve decided in this specific example to deploy the schemas of those components to three individual databases, all inside a single SQL Server instance. Whenever we want to scale out, we could decide to take one database out of this SQL Server instance and move it onto its own SQL Server instance, with better hardware (or better computer-, service- and/or hardware tiers in the cloud).
But we could also decide to deploy the schema of each individual component (orders, products, and inventory) into a single database. The result could be visualized in a new physical view like this:
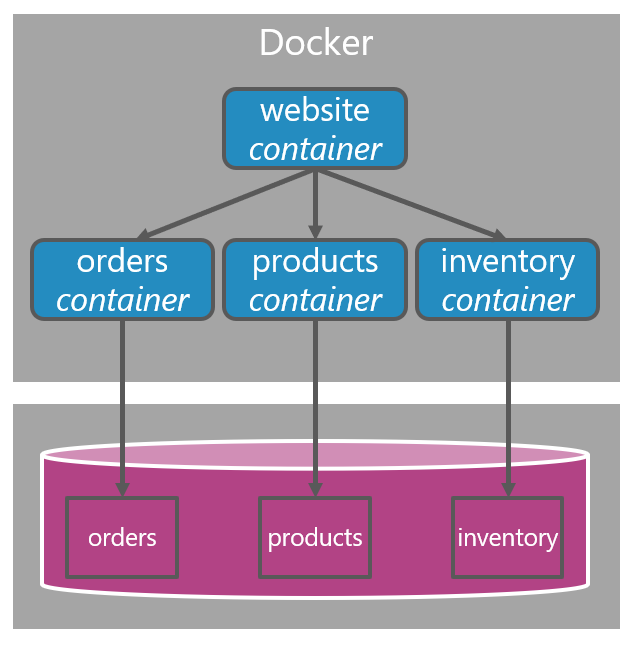
The important part is, the logical view does not change! We’ve made a decision that does not alter our architecture. We made a decision that alters our physical view. The connection string (if you will) that all three components now use, is exactly the same. But there’s no way for each individual component/container to access the data of any other component. Because we didn’t design and develop the components like that. The Orders component has zero knowledge about the schema of Products nor Inventory. It is literally unable to access that data.
Of course, if we log into SQL Server, we can write queries that can join the schema/tables that logically belong to each component. But when we had different databases, we could the exact same thing by using the database name and schema in our query. Better yet, (at least) on-premise, we can create linked servers inside SQL Server and write queries that cross servers. Most of the time that’s not a recommended way of working, but it is possible. So this way of deploying schema and data isn’t suddenly adding cheats to query across specific boundaries. That was always already possible.
Taking it a step further
But if we can deploy schema/tables like this and combine all of them inside a single database, why can’t we do exactly the same with our components and host them inside a single Docker image? Or if it’s hosted on a single virtual machine, host all of them there? Or if it’s a Windows background service, host all of them there? And so on…
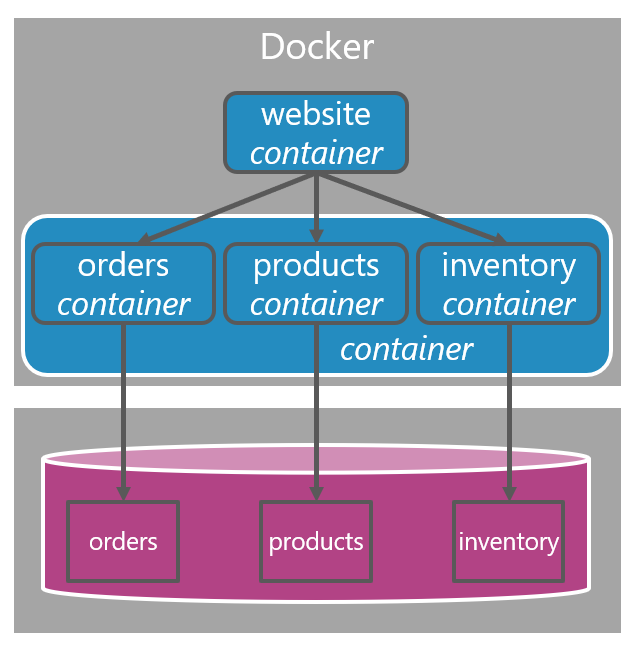
Or even better, include the website in the same image and deploy everything as a single unit. Both options don’t prevent you from taking the components out again or prevent you from horizontal scaling. But if currently there is no need for scaling out, or any other reason to indeed individually deploy each component, why would you? There’s less need for complex deployment scripts, a complex monitoring solution, and so on.
But rules are rules
I’m not saying the Orders, Products, and Inventory components are microservices. But they could very well be.
I’ve heard it mention before, that deploying this way is not according to the rules of microservices. Each microservice should be individually deployable. I’m not saying the above Orders, Products, and Inventory components are microservices. And I’m also not saying you shouldn’t have the possibility to deploy each microservice individually. But again, if there’s no need, why would you? I recently even learned that a company had a database for each of its microservices, even if a microservice didn’t store any data. Because the rules they followed, that said that every single microservice should have a database. So they created a database, even though it didn’t contain any schema or data.
Don’t blindly follow a set of rules. There are no solutions, only trade-offs.
Back to Amazon Prime
Let’s have another look at what Amazon Prime mentioned in their article.
Conceptually, the high-level architecture remained the same. We still have exactly the same components as we had in the initial design.
Could we make the conclusion that their logical architecture didn’t change and that it’s possible only their physical view changed?